AI 问数功能指南
AI 问数 是一种能够将自然语言转换为 SQL 语句的智能分析工具,可显著提升数据库研发人员、数据分析人员及业务人员的数据使用效率。在 AI 时代,AI 问数 正逐步成为 BI 与数据库研发的核心能力之一。
主要优势
-
简化数据查询 即使不熟悉 SQL,运营或业务人员也可以通过自然语言快速完成复杂查询。
-
自动报表生成 只需描述需求,即可自动生成对应的数据结果与图表。
-
显著提升效率 减少手写 SQL 的时间成本与人为错误,提高整体研发与分析效率。
技术要求
推荐模型
受限于 AI 生成 SQL 与图表的准确性,目前强烈推荐使用 deepseek-chat 模型,以获得更稳定、准确的查询结果与可视化效果。
使用指南
Step 1:同步数据源
在使用 Chat2BI 前,首先需要配置并同步数据源连接,这是后续所有操作的基础。
操作步骤:
- 进入【数据源管理】界面
- 点击【添加数据源】按钮
- 填写数据源配置信息:
- 数据源名称(建议使用业务相关的易识别名称)
- 数据库类型(MySQL、PostgreSQL、Oracle 等)
- 连接地址、端口、数据库名
- 用户名和密码
- 点击【测试连接】验证配置是否正确
- 保存数据源配置
建议使用只读账号连接数据库,避免误操作影响生产数据。数据源配置完成后,会自动进行首次同步。
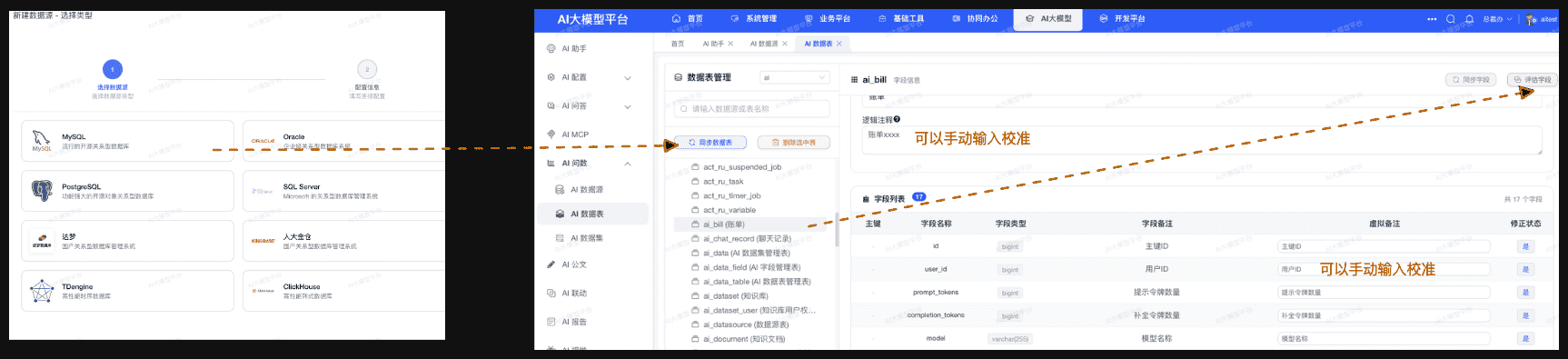
Step 2:数据表同步(学习字段和表结构)
配置好数据源后,需要同步数据库表结构,让 AI 学习并理解表结构和字段定义,这是自然语言解析与 SQL 生成的核心基础。

操作步骤:
- 进入【数据表同步】界面
- 选择已配置的数据源连接
- 点击【同步】按钮
- 系统自动拉取并解析所有表结构信息,包括:
- 表名和表注释
- 字段名、字段类型和字段注释
- 主键和索引信息
- 同步完成后,系统将展示当前可用的数据表及字段信息
当数据库结构发生变更(如新增表、新增字段、修改字段含义)后,请务必重新同步,以确保 AI 使用的是最新结构。否则可能导致查询失败或结果不准确。
字段学习原理:
系统在同步表结构时,会将表名、字段名、字段注释等信息存储到数据库中,供 AI 模型在生成 SQL 时进行语义匹配。字段注释的准确性直接影响 AI 对业务含义的理解。
Step 3:数据集字段评估(可选但推荐)
字段评估是确保 AI 正确理解数据语义的核心步骤,强烈建议执行。
通过大模型对原始字段注释进行智能校正和语义优化,可显著提升自然语言识别与 SQL 生成的准确率。
操作步骤:
- 进入数据集详情页,点击【字段评估】
- 系统自动调用 PIG AI 大模型,对字段备注进行语义优化
- 对于枚举类字段(如状态、类型),请手动维护【虚拟备注】,例如:
status字段:0-禁用,1-启用order_type字段:1-普通订单,2-预售订单,3-团购订单
- 确认并保存字段评估结果
字段描述越贴近真实业务语义,AI 理解能力越强。建议对核心业务字段进行人工校验和优化。
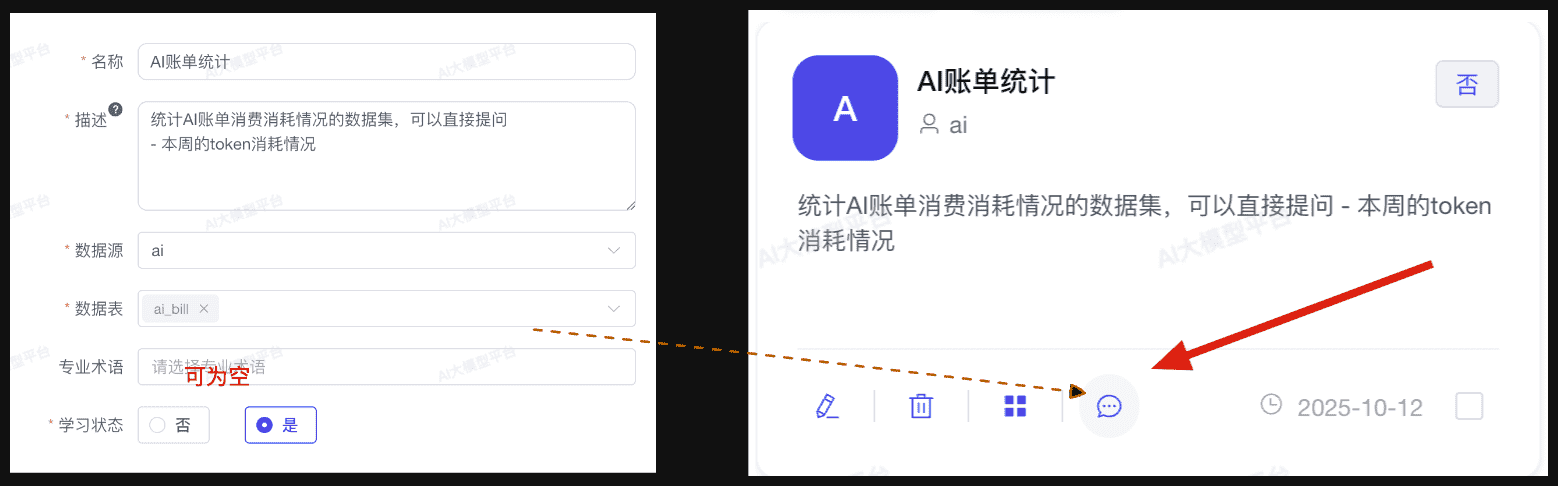
Step 4:创建数据集
创建数据集是 Chat2BI 使用过程中非常关键的一步,合理的数据集设计将直接影响自然语言查询的准确性与 SQL 生成质量。
操作步骤:
- 点击【创建数据集】
- 填写数据集基本信息:
- 数据集名称(如"订单分析数据集"、"用户行为分析")
- 数据集描述(详细说明该数据集的业务用途)
- 选择已同步的数据表(支持单表或多表关联)
- 配置表关联关系(多表时需要设置 JOIN 条件)
- 保存后,数据集即可用于自然语言查询
数据集建议按业务主题划分(订单分析、用户分析、财务分析等),单个数据集包含 3-10 张表。数据集命名与描述越清晰,自然语言提问的准确率越高。
数据集创建后,系统会将数据集的名称和描述进行向量化存储。当用户提问时,如果没有指定数据集,系统会通过向量相似度自动匹配最相关的数据集。
Step 5:向数据集提问
完成数据集创建后,就可以开始使用自然语言向数据集提问了。系统会自动将您的问题转换为 SQL 语句并执行查询。
操作步骤:
- 进入 Chat2BI 对话界面
- 选择目标数据集(也可以不选,系统会自动匹配)
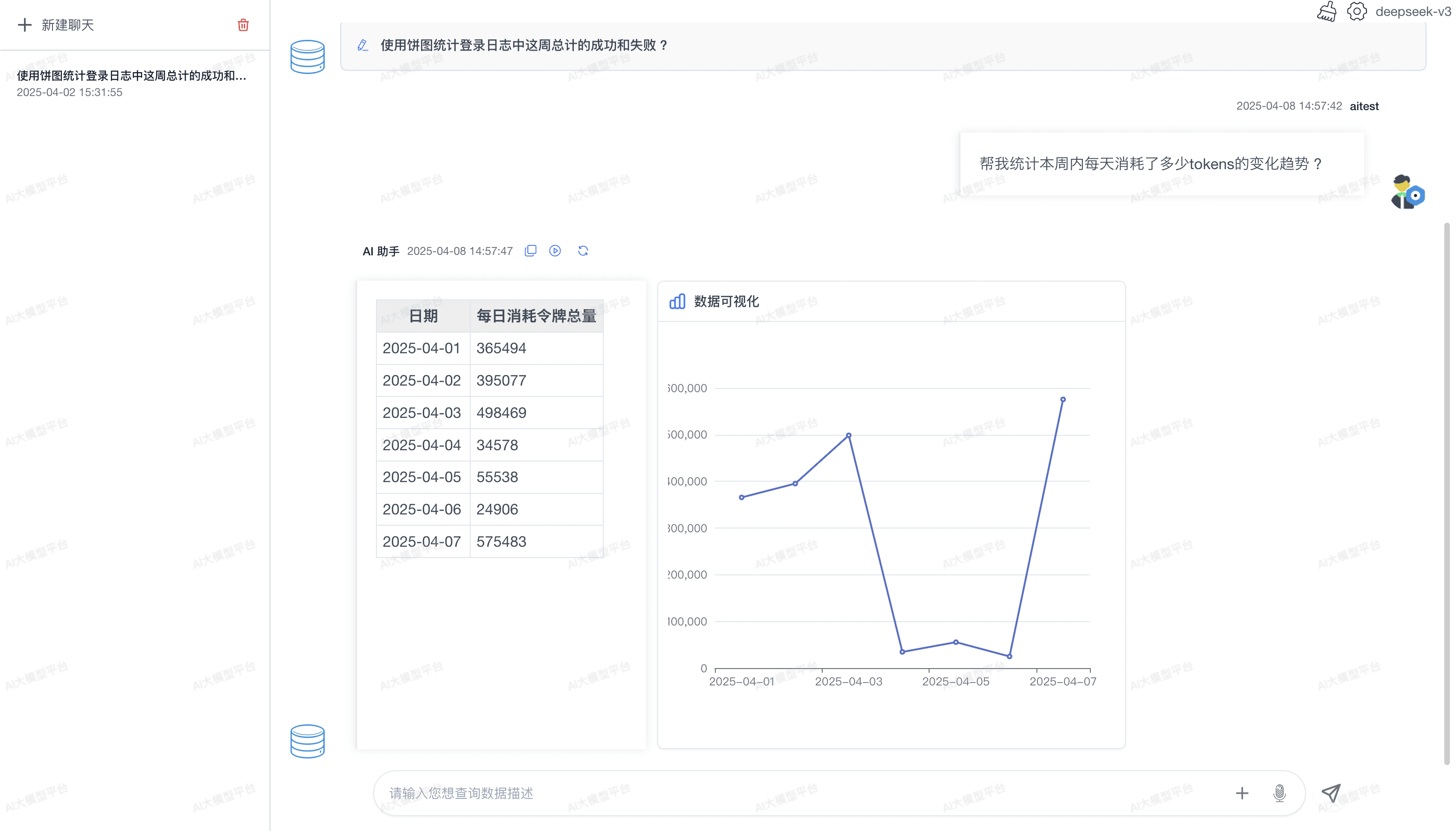
- 在输入框中使用自然语言描述您的查询需求,例如:
- "查询最近 7 天的订单总额"
- "统计各个城市的用户数量,按数量降序排列"
- "分析最近一个月销售额 TOP 10 的商品"
- "生成本月每日订单金额趋势图"
- 点击发送或按回车键
- 系统处理流程:
- 语义理解:AI 分析您的问题意图
- 数据集匹配:自动选择或使用您指定的数据集
- SQL 生成:根据表结构和字段信息生成 SQL 语句
- SQL 执行:执行查询并返回结果
- 结果展示:以表格或图表形式展示查询结果
- 如需图表展示,可在问题中明确说明图表类型,如"生成柱状图"、"生成折线图"等
如果未指定数据集,系统会基于向量相似度自动匹配最相关的数据集。建议在提问时包含明确的业务场景描述,以提高匹配准确率。
系统返回内容:
- 查询结果:以表格形式展示查询数据
- 生成的 SQL:显示实际执行的 SQL 语句(可选)
- 图表展示:根据数据自动生成图表(如折线图、柱状图、饼图等)
- 相似问题推荐:系统会异步生成相关的推荐问题,帮助您深入分析数据
为保护数据库性能,系统会对查询结果条数进行限制。如需导出完整数据,请使用导出功能。
Step 6:配置 AI 术语(可选但推荐)
AI 术语是帮助 AI 理解行业专业术语和业务黑话的关键配置,可显著提升特定领域的查询准确性。
作用说明:
在实际业务场景中,往往存在大量行业术语、业务缩写或内部黑话。例如:
- 电商行业:"GMV"(成交总额)、"UV"(独立访客)、"CVR"(转化率)
- 金融行业:"AUM"(管理资产规模)、"ROI"(投资回报率)
- 企业内部:"日活"(日活跃用户数)、"漏斗"(转化漏斗)
如果不配置术语映射,AI 可能无法正确理解这些专业词汇,导致查询失败或结果错误。
配置步骤:
- 进入数据集详情页
- 点击【AI 术语配置】
- 添加术语映射关系:
- 术语名称:GMV
- 术语解释:成交总额,即订单金额的总和
- 对应字段:order_amount
- 保存术语配置
- 配置完成后,用户可以直接使用"查询本月 GMV"等自然语言提问
配置的术语会在生成 SQL 时传递给 AI 模型,帮助模型理解特殊词汇的含义。例如,当用户问"统计本月 GMV"时,AI 会根据术语配置理解为"统计本月订单金额总和"。
使用流程
完整的 Chat2BI 使用流程如下:
Chat2BI 基于 LangChain4j 和 Spring AI 框架实现,通过语义相似度匹配和 JSON Schema 约束确保 SQL 生成的准确性。
数据集自动匹配
当用户未指定数据集时,系统会通过以下步骤自动匹配:
- 向量化用户问题:将用户的自然语言问题转换为向量表示
- 相似度搜索:在向量数据库中搜索与问题最相似的数据集
- 自动选择:选择相似度最高的数据集进行查询
- 上下文更新:将匹配的数据集 ID 更新到对话上下文中
如果未找到相关数据集,系统会提示"未找到相关数据集建模,请点击下方+按钮选择目标数据集合"。此时需要手动选择数据集或创建新的数据集。
图表生成
Chat2BI 支持自动生成多种类型的图表:
| 图表类型 | 适用场景 | 提问示例 |
|---|---|---|
| 折线图 | 趋势分析、时间序列 | "生成最近30天订单金额趋势折线图" |
| 柱状图 | 分类对比、排名 | "统计各城市销售额,生成柱状图" |
| 饼图 | 占比分析、构成 | "分析各商品类目销售占比,生成饼图" |
| 表格 | 明细数据、详细列表 | "查询最近10条订单明细" |
系统会根据查询结果的数据特征自动推荐合适的图表类型。您也可以在提问时明确指定图表类型。
相似问题推荐
系统在返回查询结果后,会异步生成相似问题推荐,帮助用户进行数据的深度探索:
- 生成时机:在主查询结果返回后异步生成,不影响主查询性能
- 生成逻辑:基于当前问题、表结构和查询结果,使用 AI 生成相关的推荐问题
- 数量控制:通常推荐 3-5 个相关问题
- 点击使用:用户可直接点击推荐问题进行查询
相似问题生成基于 SimilarQuestionHelper.generateSimilarQuestionsForDatabase() 方法,使用 Reactor 异步流式推送,确保不阻塞主查询流程。
模型与安全
推荐模型
受限于 AI 生成 SQL 与图表的准确性,目前强烈推荐使用以下模型:
- DeepSeek V3(首选,性价比高)
- Qwen3-Max
- Kimi K2
- GLM 4.7 其他模型可能导致 SQL 生成不准确或图表展示异常。
数据安全
- 建议使用只读账号连接数据库,避免 AI 生成修改或删除类 SQL
- 系统会对生成的 SQL 进行基本校验,但不保证 100% 安全
- 敏感数据库请谨慎使用,建议先在测试环境验证
- 查询结果会受到租户隔离和权限控制的约束